Breve guida alla compressione video
A pochi mesi dalla prima stesura, ecco la versione 1.1 della mia guida alla compressione video, dedicata sia a coloro che si stanno affacciando al mondo del montaggio video, sia coloro che hanno più esperienza, ma ancora qualche dubbio. Il linguaggio è chiaro e semplice, quindi anche i “non addetti ai lavori” potrebbero trovare interessanti gli argomenti trattati. Vi invito a consultare le note che ho inserito, per approfondire e consolidare le conoscenze.
1 Cos’è un codec?
2 La compressione video
2.1 Interlacciato vs. progressivo & framerate
2.2 Compressione video lossy: intraframe vs. interframe
2.3 Compressione video lossless
Note
Cos’è un codec?
Un codec (abbreviazione di compressor-decompressor) è un programma che comprime/decomprime un file audio/video per ridurne la dimensione. La decompressione avviene ogni volta che il file dev’essere letto o riprodotto.
Spesso si fa confusione tra codec e formato. Quest’ultimo è un contenitore (container o wrapper) che può avere al suo interno diversi flussi (streams) video e audio (ma non solo, pensate ai sottotitoli) . Il codec può essere anche definito “formato video” mentre il formato può essere indicato come “formato documento”. Certi codec funzionano meglio in particolari container, mentre non funzionano affatto in altri (è difficile trovare un flusso video codificato in H.264 in un contenitore .avi). [1] [2] [3]
Soprattutto molti anni fa (meno di quanti si possa immaginare), quando l’ADSL era un sogno futuristico e i dispositivi di archiviazione erano agli antipodi, ridurre le dimensioni di un file non era un’opzione, bensì un bisogno.
I codec possono lavorare in due modi:
- Codec lossy: riducono la dimensione dei file perdendo informazioni dell’originale;
- Codec lossless: riducono la dimensione dei file senza perdere nulla dell’informazione informazione originale.
Nel primo caso la qualità del file compresso è peggiore di quella del file originale. Si può parlare di compressione “distruttiva”. Le informazioni rimosse, generalmente, non sono “critiche”: per esempio nel caso degli MP3 le informazioni scartate consistono nei suoni non udibili (ma se la compressione è “eccessiva” il peggioramento di qualità diventa consistente e percepibile) mentre nel caso delle immagini JPEG i gruppi di pixel attigui e simili cromaticamente possono essere accorpati in blocchi più grandi, perdendo una certa quantità di dettagli a seconda della quantità di compressione effettuata. Bisogna tener presente che le informazioni perse durante la compressione non sono recuperabili successivamente.
Nel secondo caso la compressione non porta a perdite di dati, quindi, ad esempio, è un sistema utile per i file testuali (per i quali non sarebbero accettabili perdite di informazioni!). Parliamo in questo caso di compressione “non distruttiva”. Ma come si fa a comprimere un file senza perdere dati? Eliminando le informazioni ridondanti[4]. Un esempio di compressione lossless è quella RLE (Run Lenght Encoding): l’algoritmo individua nel file da comprimere delle sequenze (run) che si ripetono costantemente, quindi le sostituisce con un unico simbolo e con il numero di ripetizioni presenti.
Ecco un esempio di compressione non distruttiva di un immagine: se una larga zona di una foto è completamente nera, una algoritmo lossless potrebbe accorpare tutti i pixel neri senza dover scrivere le informazioni per ognuno di essi. Nella decompressione dell’immagine la zona nera sarebbe identica all’originale, bit per bit. Bisogna ricordare infatti che la compressione lossy avrebbe accorpato anche i pixel quasi neri, e questa piccola differenza sarebbe scomparsa nella copia compressa e non sarebbe stata più recuperabile.
Il PNG (Portable Network Graphics, ma può essere letto anche come un acronimo ricorsivo per “PNG’s Not Gif”) è un formato di compressione d’immagine non distruttiva estremamente diffuso. L’algoritmo alla base di PNG è molto potente – i risultati che si ottengono sono in genere del 20% migliori di quelli ottenibili con la compressione GIF. Inoltre vi è il supporto per i canali alfa: ogni pixel può avere una trasparenza variabile su 254 livelli di opacità. Quest’ultima caratteristica ha garantito al PNG grande fortuna tra i webdesigner. [5]
La compressione video
A questo punto viene da chiedersi: come vengono compressi i video? Prima di tutto bisogna distinguere tra l’immagine analogica televisiva, e quella digitale (per esempio le immagini in alta definizione).
Interlacciato vs. progressivo & framerate
Un video è un’insieme di immagini fisse visualizzate in rapida sequenza. La velocità di riproduzione dev’essere abbastanza alta per sfruttare il fenomeno della persistenza della visione, ovvero il sistema che adotta il nostro cervello per “assemblare” le immagini e percepire un movimento fluido tra i fotogrammi.
Ogni immagine (fotogramma) del video può essere visualizzato secondo due metodologie diverse di scansione: la scansione interlacciata (interlacciamento), e la scansione progressiva.
L’immagine televisiva è costituita da 576 linee orizzontali (nel sistema PAL) ed ogni fotogramma è il risultato di una scansione da sinistra verso destra e dall’alto verso il basso. La scansione è interlacciata, quindi prevede la divisione delle linee di scansione di ognuno dei 25 fotogrammi – visualizzati ogni secondo – in due “parti” dette campi (fields). Ogni fotogramma quindi contiene due campi che costituiscono due istanti temporali diversi, e questo comporta che la frequenza di fotogrammi percepita sia più alta (50 al secondo). 25 campi sono pari e 25 dispari. In altre parole, per ogni fotogramma le linee pari costituiscono un istante temporale, quelle dispari quello successivo (o precedente, a seconda del sistema utilizzato). Durante la riproduzione del segnale, i 25 fotogrammi vengono deinterlacciati in modo che vengano mostrati tutti e 50 i semiquadri consecutivamente. Grazie a questo sistema, sfruttando il fenomeno della persistenza della visione di cui sopra, si evita che sia percepito uno sfarfallio dell’immagine che i soli 25 fotogrammi al secondo produrrebbero, rimanendo però all’interno dei limiti imposti dalla banda di segnale ristretta.
Negli anni molte volte si è provato ad abbandonare il sistema che prevede l’interlacciamento, ma senza grande successo. L’avvento dei televisori in Alta Definizione è uno degli elementi che hanno dato una spinta all’utilizzo della scansione progressiva.
- PAL: 50 campi al secondo, 625 linee, campi dispari disegnati per primi;
- SÉCAM: 50 campi al secondo, 625 linee;
- NTSC: 59,94 campi al secondo, 525 linee, campi pari disegnati per primi;
- PELLICOLA: 24 fotogrammi al secondo.
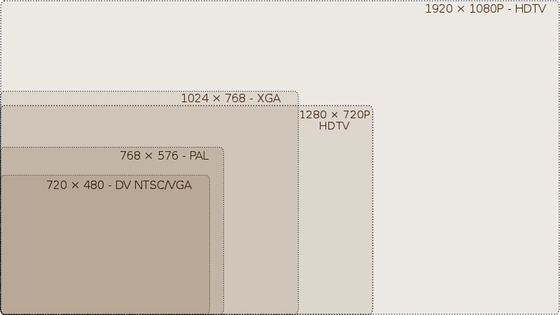
L’immagine digitale invece è suddivisa in pixel. Una linea TV si considera costituita da 720 pixel, pertanto un’immagine TV è formata da 720 pixel in larghezza per 576 pixel in altezza. Un’immagine HD può avere una risoluzione di 1280×720 pixel (detta 720p) oppure 1920×1080 (1080p, detto anche Full HD). Anche immagini di questo tipo, in realtà, possono essere interlacciate: si tratta delle risoluzioni 720i e 1080i. In questo caso l’interlacciamento può essere sfruttato a proprio vantaggio, ma questa è un’altra storia. [8]
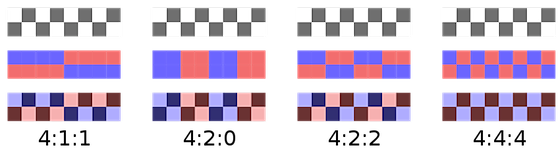
Ad ogni pixel dell’immagine televisiva digitale sono associati i valori di informazione luminosa dell’immagine, la luminanza (Y), e i valori relativi al colore, la crominanza (C). Il rapporto tra campioni di luminanza e crominanza è determinato dallo schema di sottocampionamento della crominanza, ovvero un sistema che permette di riservare maggiore risoluzione al segnale di luminanza piuttosto che a quello/i di crominanza. Gli schemi maggiormente usati sono tre: 4:2:2, 4:1:1 e 4:2:0. Il primo è lo standard de facto per l’interscambio dei programmi e la diffusione tv, mentre gli altri due incidono maggiormente sulla qualità dell’immagine. [9]
Compressione video lossy: intraframe vs. interframe
Se la compressione è di tipo lossy, ogni singolo fotogramma è diviso in blocchi e sotto-blocchi (per esempio rispettivamente di 16×16 pixel e 8×8 pixel). L’algoritmo della compressione cerca di fondere il colore dei blocchi più piccoli in un solo pixel, applicando poi la stessa procedura ai blocchi più grandi. Se la fusione è lieve, la qualità dell’immagine è ottima. Viceversa se la fusione è elevata, la qualità è scarsa. Ingrandendo il fotogramma di un video compresso ed aumentandone la nitidezza i blocchi di cui sopra saltano all’occhio.


Fotogramma estratto da LOST di J. J. Abrams.
La “blocchettatura” può essere fastidiosa, degradando eccessivamente la qualità di un video. Vi ricordo che la compressione video di cui stiamo parlando è di tipo lossy, quindi da quei blocchi non è possibile risalire in nessun modo ai dettagli originali. Nonostante ciò esistono alcune tecniche per recuperare in parte la qualità di un video compresso, come appunto il deblocking. [10]
Cosa distingue la compressione dei video da quella delle immagini statiche? Semplificando molto, il fatto che non tutti i fotogrammi sono compressi nello stesso modo. Generalmente, infatti, in un filmato possiamo distinguere 3 tipi di fotogrammi:
- I-frame (Intra coded picture o Intra frame): sono fotogrammi compressi autonomamente che quindi contengono la maggior parte di dettagli e informazioni;
- P-frame (Predictive coded picture o Predictive frame): qui avviene la cosiddetta compressione interframe, grazie alla quale il fotogramma viene confrontato col precedente/i e viene quindi descritto dall’algoritmo in base differenze con questi ultimi. Le parti d’immagine statiche vengono solo “richiamate”, mentre quelle che hanno subito spostamenti o altre modifiche vengono descritte in base ai movimenti, alle rotazioni, agli schiarimenti ecc.; si tratta quindi di compressione a codifica differenziale;
- B-frame (Bidirectional predictive coded picture o … frame): sono i fotogrammi maggiormente compressi in quanto la loro struttura è ricostruita sia in base ai fotogrammi precedente che a quelli successivi.
Il particolare ordine in cui i tre tipo di fotogrammi sono disposti si chiama GOP, ovvero group of pictures. Ogni flusso video è costituito da una sequenza di GOP.
Ogni GOP comincia con un I-frame, seguito da più P-frames. Negli spazi rimanenti ci sono i B-frames. Alcuni codec prevedono più di un I-frame in ogni GOP. Un codec con diversi I-frames può andare bene per piccoli montaggi video. Un esempio di struttura GOP è IBBPBBPBBPBBI, che possiamo scrivere anche in questo modo: M=3 N=12 (dove M è la distanza tra gli anchor frames I o P mentre N è la distanza tra I-frames)

L’immagine qui sopra è un esempio di funzionamento della compressione interframe: sopra ci sono i fotogrammi così come appaiono sullo schermo; sotto vengono mostrati solo i cambiamenti tra essi. Sostanzialmente quello che cambia è la sedia in movimento, mentre viene ridisegnato lo sfondo nelle aree dalle quali la stessa si è spostata. Come è evidente, lo svantaggio risiede nel fatto che per visualizzare, per esempio, il quinto fotogramma (che è un P-frame), è necessario partire dal primo e rielaborare tutti i cambiamenti avvenuti fino al quinto. Se questo fosse un GOP, sarebbe “IPPPP”. [11]
Siamo quindi arrivati ad un punto delicato ed importantissimo del discorso. La compressione interframe costituisce un problema per il montaggio video. Immaginate infatti di inserire tagli o fare altre modifiche in punti del filmato costituiti da predictive frames (peggio se bidirectional). Il nostro software di montaggio sarà costretto a calcolare il contenuto di questi fotogrammi numerose volte, rallentando il rendering e il playback.
Il DV è un esempio di codec che utilizza compressione intraframe (come se il video fosse una semplice sequenza di immagini). Fare tagli nei video con compressione intraframe è come fare tagli su video non compresso (uncompressed). Il problema è che nei video compressi in questo modo, tutti i fotogrammi contengono più o meno la stessa quantità di dati – mentre, come è facile intuire, nel caso della compressione interframe ci sono i P-frames e i B-frame che contengono molte meno informazioni degli I-frames – ergo hanno dimensioni consistenti.
Un altro esempio di compressione lossy intraframe, che questa volta riguarda direttamente chi utilizza Final Cut, è la famiglia di codec Apple ProRes. [12] Introdotti per la prima volta nell’aprile del 2007, questi codec sono pensati proprio per rendere possibile (e fattibile) l’editing di materiale full-frame a 10 bit in Alta Definizione 4:2:2 con performance real-time. La dimensione dei file non è eccessiva grazie al bitrate variabile. Questa pagina, recentemente pubblicata da Apple, chiarisce ogni dubbio sulle differenze tra i vari codec della famiglia.
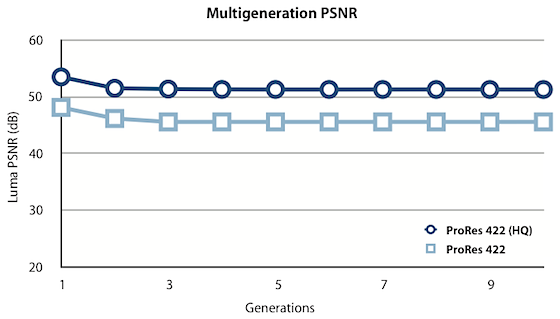
Questi codec hanno anche un altro vantaggio. Dopo diversi passaggi di decompressione e ricompressione, l’immagine risulta ancora visivamente identica all’originale, come mostrato da questo grafico.
Compressione video lossless
Passiamo ora alla compressione video lossless. Il video decompresso, in questo caso, è perfettamente identico, bit per bit, all’originale. Questi codec non vengono utilizzati frequentemente, a differenza di quelli lossy che permettono di ottenere risultati di qualità elevata occupando molto meno spazio su disco.
Alcuni particolari codec più leggeri (in quanto lossy) ma adatti al montaggio (quindi con compressione intraframe) vengono utilizzati nelle fasi intermedie di lavorazione, per esempio, di un film o altri prodotti mediali. Sto parlando dei cosiddetti codec intermediate, che garantiscono alta qualità e performance facendo sforzare relativamente poco la CPU rispetto ai formati più compressi. Sono codec pensati per l’utilizzo nel montaggio video, e non per la fruizione finale. Un esempio di ‘intermediate codec’ sono proprio gli Apple ProRes.
C’è in realtà anche un codec intermedio tra lossy e lossless, detto virtually lossless. Prima ho scritto della ‘famiglia ProRes’: un esempio di codec virtually lossless è proprio un membro di questa famiglia, ovvero l’Apple ProRes 4444, il codec con la banda più ampia e meno compresso di tutti i ProRes. [15]
Per quanto riguarda il video uncompressed, l’informazione digitale non è stata compressa. Ha un bitrate variabile di circa 30Mbits/s. Generalmente il video non compresso non viene utilizzato durante il montaggio, ma – se necessario – viene comunque sostituito al materiale intermediate prima di finalizzare il progetto.
Siamo giunti alla fine di questa breve guida, non esaustiva, sulla compressione video. Se avete domande, dubbi o suggerimenti per migliorare questo post, potete contattarmi su Twitter o su Facebook.
Se vi è piaciuto questo post vi invito a condividerlo sui social network usando i pulsanti in alto e di iscrivervi al Feed RSS.
Note:
- Breve guida sui principali codec e formati video ↩
- Discussione su TechSupport FORUM ↩
- Appunti sul Digital Video: Principianti ↩
- Elementi di base dei linguaggi di programmazione ↩
- Algoritmi di compressione per i formati grafici ↩
- Il film look per i tuoi video ↩
- The Truth About 24p Video ↩
- Ultra Slow Motion video-tutorial in Final Cut Pro X ↩
- Sottocampionamento della crominanza da ilCORTO.eu ↩
- S3 Graphics Technologies ↩
- The Ins and Outs of Video Compression ↩
- Apple ProRes White Paper (July 2009) ↩
- Formati Video: cos’è il bitrate? ↩
- DSLR Video Shooter ↩
- Motion 5 User Manual ↩